The Pilot Graveyard: Why 80% of Enterprise AI Strategy Efforts Never Make It to Production
Updated On:
May 21, 2026

The Pilot Graveyard: Why 80% of Enterprise AI Pilots Never Become Products and Why enterprise AI strategy Fails at Scale
Enterprise AI is not failing in the boardroom. It is failing in the middle - in the long, expensive stretch between a promising pilot and a working product. Organizations are running dozens of initiatives at once, with no clear criteria for what success looks like and no real system to decide what gets killed.
The result is a growing graveyard of stalled pilots that cost millions, quietly drain trust, and block the focus needed to actually ship something. The root cause is often a broken enterprise AI strategy or the absence of one entirely.
This piece breaks down why it happens, what it costs, and what fixing it actually looks like.
Where Enterprise AI Actually Stands
Picture a large organization eighteen months into its AI transformation. There are fourteen active pilots across six business units, three steering committee decks in circulation, and not a single initiative in production. This is not a hypothetical - it is the most common picture in enterprise AI right now.
The gap between AI ambition and AI delivery has never been wider. Every earnings call leads with transformation. Every board deck has an AI slide. And yet the actual numbers tell a very different story.

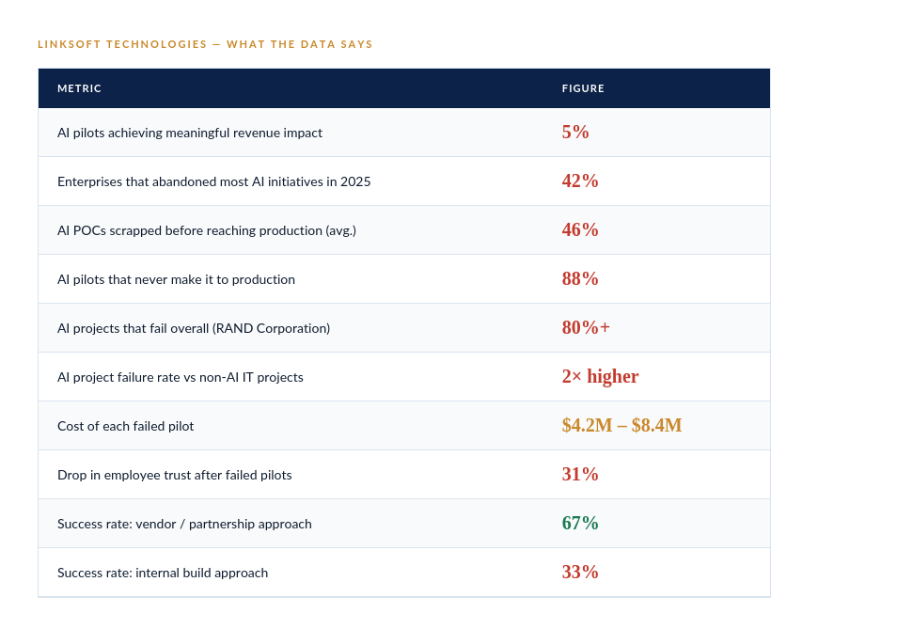
This is not a technology problem. The models work. The problem is structural - and it starts with how enterprises have chosen to organise experimentation.
Why Enterprises Are Running Too Many AI Pilot Programs at Once
Imagine a factory floor where forty machines are running at half capacity, each assigned to a different product, none of them producing enough output to fill a single order. That is what enterprise AI portfolio management looks like today. Every business unit has a pilot, every pilot has a nominal owner, and none of them has enough resources to actually cross the finish line.
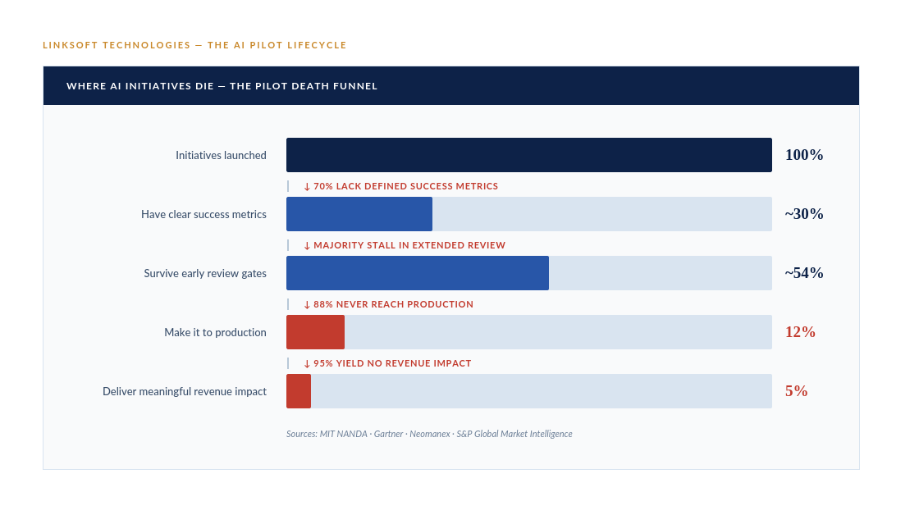
Large enterprises have developed a particular habit: launch each AI pilot program in parallel, give each a small budget, and call it a portfolio strategy. It feels diversified. It looks like momentum. What it actually is, is a resource-dilution machine.
Research from MIT Sloan Management Review found that organizations running high volumes of simultaneous pilots were significantly less likely to bring any single one to production. Each pilot needs data access, engineering bandwidth, stakeholder time, and governance attention - and spread across fifty experiments, none of these accumulates enough to matter.
The ROI math gets diluted too. When forty pilots each promise efficiency gains somewhere between 10% and 40%, none of them ever has to prove anything specific. They can all look marginally promising, indefinitely.
How to Prioritize AI Use Cases in a Company
Not every use case deserves a pilot. The organisations that prioritise well apply a simple filter before anything gets resourced: does this use case sit on a high-quality data asset, does it have a clear business metric it will move, and is there an owner willing to be accountable for that outcome?
Use cases that cannot answer all three stay off the roadmap. Those that can get sequenced by impact and feasibility with the highest-confidence, highest-value bets going first, not the ones with the most enthusiastic sponsors.
Why Failing Pilots Never Get Killed
The most common AI pilot failure mode isn't a bad model but a pilot that nobody is authorised to kill.
Think of it like a meeting nobody wants to cancel. Everyone knows it's stopped being useful. Nobody says so out loud. And so it stays on the calendar, consuming time that could go somewhere productive.
Pilots are politically safe. They signal ambition without demanding commitment. Killing one means someone has to say it failed - and letting it drift means nobody has to say anything at all.
Vendor relationships make it worse. End the pilot, and the account manager escalates, the vendor produces updated benchmarks, and someone proposes a "Phase 2 refresh." The pilot runs for another two quarters on engineering hours that could have gone toward something actually working.
Sunk Cost Panic does the rest. The fear that killing a pilot wastes the investment already made leads organizations to keep running initiatives that should have been retired months ago.
And so pilots accumulate - sitting in a permanent state of "still showing promise," consuming attention and credibility without ever producing anything real.
Why AI Projects Fail in Large Organizations Despite Heavy Investment
Investment is not the constraint. Most large enterprises spending heavily on AI are failing because money flows into the wrong places. Budgets go to model procurement and tooling; almost nothing goes to the change management, data engineering, and governance infrastructure that determines whether a model ever gets used.
The result is well-funded pilots sitting on top of underprepared organisations, producing impressive demos that never touch a real workflow.
The Real Cost of Doing Nothing
Most leaders treat a stalled pilot as a neutral outcome - no harm done, lesson learned, move on. But the cost of doing nothing is not neutral, and it shows up in places that do not appear on a standard project dashboard.
Employee trust in company-provided AI drops every time a pilot gets hyped internally and then quietly disappears. And every zombie initiative that stays alive is consuming engineering hours and senior attention that could go toward the one or two initiatives that actually have a chance of shipping.

The credibility debt is the hardest cost to recover from. Every workforce that has been promised transformation and received nothing becomes harder to mobilise for the next initiative. The skepticism compounds - and by the time the board starts asking whether the AI investment is producing anything, the answer is already two years overdue.
The cumulative picture is an organisation that has spent years on AI, has little to show for it, and is now significantly less capable of making the next push land.
What Happens When AI Projects Fail in Companies
The immediate impact is visible: wasted budget, missed deadlines, and a vendor relationship that quietly sours. The downstream damage is harder to see and far more expensive. Teams grow reluctant to raise concerns after a failed initiative, leadership credibility erodes when publicised efforts disappear, and boards promised transformation but delivered cost become more sceptical, lengthening approval cycles when speed matters most,
The Governance Infrastructure Nobody Built
Imagine buying forty plots of land with no architect, no planning permission, and no decision on which plots are worth developing. That's AI governance in most large enterprises - lots of activity, no decision-making infrastructure underneath it.
A 2024 Gartner survey found that while 80% of large organisations claim AI governance initiatives, fewer than half demonstrate measurable maturity. What they have is a responsible AI charter and a quarterly review committee. What they don't have is a framework that defines when to scale, when to kill, and who is accountable.
Nearly one-third of CIOs lack clear metrics for AI proofs-of-concept. Pilots get measured on model accuracy, not business outcomes. A pilot can hit 94% accuracy in a sandbox and still show no impact on cost, revenue, or risk. That's where most governance frameworks fall apart.
The core mistake is running pilots without defining what failure looks like upfront which is precisely why they survive indefinitely on the basis of "still showing promise."
What a Real Governance Framework Looks Like
A functioning AI portfolio governance framework is not complicated. It just requires the decisions that most organisations have been actively avoiding.
Best Practices for Scaling AI in Large Organizations
Scaling AI is about building infrastructure that makes each successive initiative faster and cheaper. Organisations that scale effectively establish shared data and integration layers, standardise model evaluation so teams define what "working" means consistently, and treat MLOps, monitoring, retraining, and incident response for live models, as a core platform investment. Scaling follows depth: one domain done properly becomes the template for the next ten.

The sequencing piece is worth emphasising. Rather than launching broadly, the most effective organisations go deep in a single domain first - building the data governance, integration patterns, and change management muscle that makes every subsequent domain faster and cheaper. Breadth comes after depth, not instead of it.
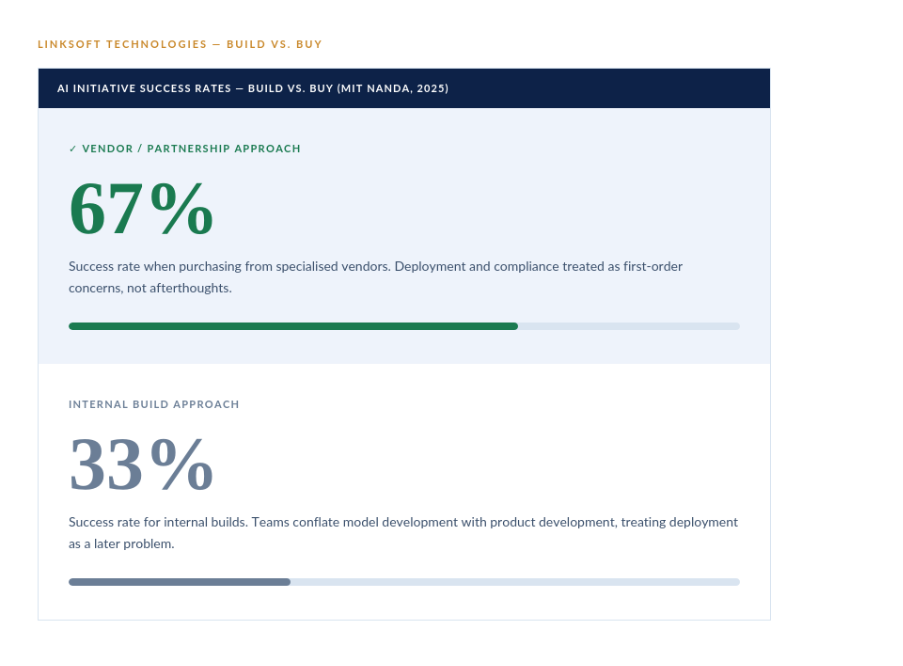
The build-vs-buy question follows the same logic. Purchasing from specialised vendors and building partnerships succeeds 67% of the time. Internal builds succeed one-third as often - not because internal teams are less capable, but because internal builds tend to conflate model development with product development, spending enormous cycles on the former while deployment and compliance get treated as a later problem. They are not a later problem.
The Companies Moving Fastest Kill Things Fastest
The organisations winning on AI share a counter-intuitive characteristic: they kill things faster. Not because they're better at failure but because they've built the infrastructure to make clean, fast decisions and treat that decisiveness as a competitive advantage.
The startups leaping to tens of millions in revenue within a year have one consistent edge: ruthless focus. Enterprises replicating this posture - fewer initiatives, deeper execution, explicit decision gates - are the ones actually compounding an AI advantage.
The practical shift isn't complicated. Define what done looks like before the kickoff call. Name the person who can call a pilot dead and give them the authority. Set a portfolio ceiling and enforce it. Measure outcomes against business metrics, not benchmark scores. A fast, clean kill is a sign of organisational health - not a failure of ambition.

What Is the Real Success Rate of Enterprise AI Projects and How Do You Move from Pilot to Production?
80–85% of enterprise AI projects never reach production or fail to deliver measurable value after deployment, as McKinsey & Company and Gartner consistently show. This pattern of AI pilot failure is systemic, not accidental.
The failure mode is quiet - projects stall in perpetual pilot status when adoption never materialises. Moving from pilot to production requires what teams skip: a dedicated production owner, an integration plan tied to real data pipelines, compliance sign-off from week one, and a rollback protocol.
Organisations that succeed define a production brief before the pilot - clear business metric, ownership, and shutdown criteria - because the gap is not technology, but organisational design.
The Bottom Line
The era of portfolio breadth as an AI strategy is over. More pilots do not produce more value. They produce more distraction, more sunk cost, more trust erosion, and more ammunition for the board member who wants to ask whether the AI investment is actually doing anything.
The organisations that compound their AI advantage over the next three years will not be the ones that ran the most experiments. They will be the ones that built the infrastructure to decide faster - and had the discipline to go deep on the things worth building, and let go of everything else quickly.
The graveyard is not growing because enterprises lack ambition. It is growing because they have no framework to decide what lives and what dies. AI pilot failure at this scale is entirely fixable - it just requires one conversation most organisations have been avoiding: what does failure actually look like, and who is authorised to call it? The investment was undercounted from the start — and that's the conversation most business cases never forced anyone to have.