
Why AI Fails at Scale: The AI Readiness Problem Every Enterprise Is Ignoring
Updated On:
May 29, 2026

Almost every enterprise has deployed AI. Almost none have built the system underneath it that would actually let it work. That gap is where most of the money is quietly disappearing.
Enterprise AI has an adoption problem nobody wants to say out loud. Not too little adoption but too much of the wrong kind.
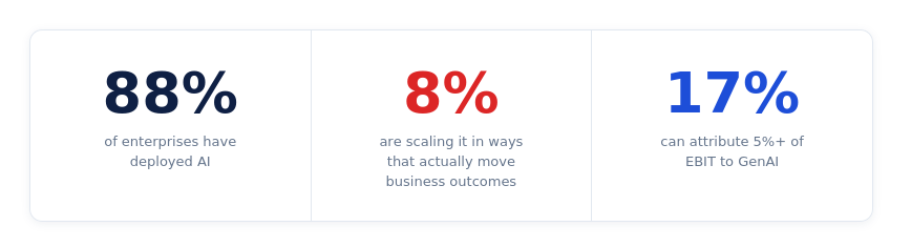
88% of companies have deployed AI. Only 8% are scaling it in ways that actually move business outcomes (Source: Accenture, The Front-Runners' Guide to Scaling AI). That gap is where billions of dollars are quietly disappearing. The reason almost nobody names clearly: the model isn't the problem. The system underneath it is.
Most boardrooms are still debating the wrong things. The AI implementation conversation starts at the model. It should start at the system.
Which model to use, which vendor to trust, which use case to pilot next - these are real questions - completely downstream of a more fundamental one nobody is asking: was this ever built to scale, or just built to impress in a demo?
Those are two very different things and confusing them is the most expensive mistake in enterprise AI right now.
Why Pilots Work and Deployments Don't?
The enterprise AI playbook feels logical. Pick a capable model, find a high-value use case, run a pilot, show results, scale. Nearly half of enterprise AI projects fail at that last step, not because the model underperformed, but because the system underneath it was never built to hold up under real conditions.
Putting AI on a broken process is like putting GPS on a car with a broken engine. The navigation is flawless but you're still not going anywhere. Teams still wait on manual approvals, ownership remains unclear, and employees end up validating outputs across multiple disconnected systems.
The proof of concept works because it's a controlled environment - clean data, cooperative stakeholders, no real workflow pressure. Production is none of those things. Production is where data pipelines are inconsistent, governance structures don't exist yet, and the integration between AI outputs and actual business workflows was never properly designed.
Why Do Most Enterprise AI Projects Fail to Scale After Successful Pilots?
Pilots are controlled environments - clean data, cooperative stakeholders, no real workflow pressure. Production is none of those things, the model doesn't change between the two. The system around it does and that's what breaks.
Stanford HAI's 2026 AI Index found hallucination rates across top models ranging from 22% to 94% (Source: Stanford HAI, 2026 AI Index Report). AI hallucination at that scale isn't a model quirk but a deployment infrastructure failure.

The Infrastructure Gap Nobody Budgets For
The appliance analogy is direct: you can buy the most advanced equipment in the world. In a showroom with stable power, it works perfectly. Plug those same appliances into a building with inconsistent wiring, insufficient capacity, and no circuit protection and they fail. The appliances look like the problem, the wiring is the actual problem.
The cost of that delay compounds in ways most organizations never fully account for - a problem we break down in detail in The $18 Million Hidden Cost of Not Modernizing Your Enterprise Systems.
For AI, the wiring is your data readiness, your integration architecture, your governance controls, and whether your workflows have actually been redesigned to absorb what AI produces. Most organizations buy the appliances. Almost none fix the wiring first.
Why Are Companies Adopting AI But Not Seeing Measurable Business Results?
Because adoption and readiness are two different things, and most organizations are measuring the wrong one. Buying a model is not the same as building the system that lets it work. The infrastructure gap - data readiness, integration architecture, workflow redesign - is where the returns disappear, long before anyone looks for them.
It's the actual reason 92% of enterprises are running AI without proportional returns (Source: Accenture, The Front-Runners' Guide to Scaling AI).
What Infrastructure Is Required Before Deploying AI at Enterprise Scale?
Data pipelines that are consistent and governed. Integration architecture that connects AI outputs to actual business workflows. A development lifecycle built for probabilistic systems, not deterministic ones. And workflows that have been redesigned - not just automated. Most organizations have none of these in place before they deploy.
Where Deployments Break Down
Governance that identifies risk but can't contain it. Most organizations have a responsible AI charter and maybe a quarterly review committee. What they don't have is a framework that tells anyone what to do when the model produces something wrong in a live workflow. McKinsey's 2026 AI Trust Survey found that 74% of organizations flag AI inaccuracy as a major risk - AI hallucination chief among them, 72% flag cybersecurity, and almost none have infrastructure to manage either at scale (Source: McKinsey & Company, Global AI Trust Maturity Survey).
Testing built for the wrong kind of system. Traditional QA assumes the same input produces the same output. AI doesn't work that way. A model in production is probabilistic. Its failure modes aren't binary, and its performance degrades in ways standard testing was never designed to catch. Deploying AI through a traditional software development lifecycle creates a fundamental mismatch between the tool and the process meant to validate it.
In most organizations, AI gets inserted into approval chains, reporting structures, and handoffs nobody redesigned first. The result is usually faster execution of the same underlying inefficiency. Broken handoffs, redundant steps, approval processes nobody questioned.
How Should Enterprises Redesign Workflows Before Implementing AI?
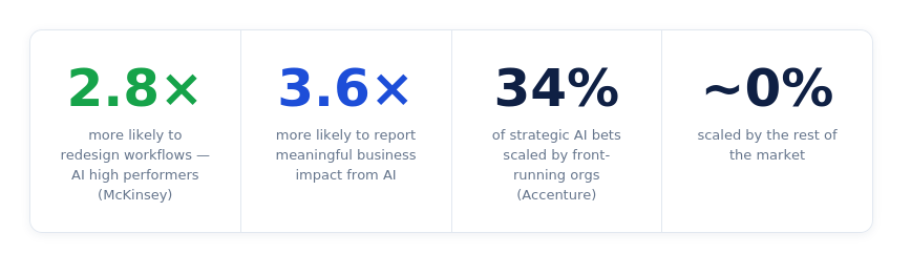
Start by mapping every workflow AI will touch - not to automate it, but to question it. Broken handoffs, redundant steps, approval processes nobody challenged - AI executes all of it, faster. The redesign has to happen before deployment, not after. McKinsey found AI high performers are 2.8x more likely to fundamentally redesign workflows before going live.

The Lifecycle Mismatch
Most enterprises are trying to run AI on infrastructure that was never designed for it. The traditional SDLC was built for deterministic systems - same input, same output, test it, ship it, maintain it. That model worked for decades. It doesn't work for AI.
What Is AI System Readiness and Why Does It Matter for Enterprise Deployment?
AI system readiness is the infrastructure layer beneath the model - governance, data quality, integration design, lifecycle management, and workflow architecture. Without it, the model runs but the system doesn't.
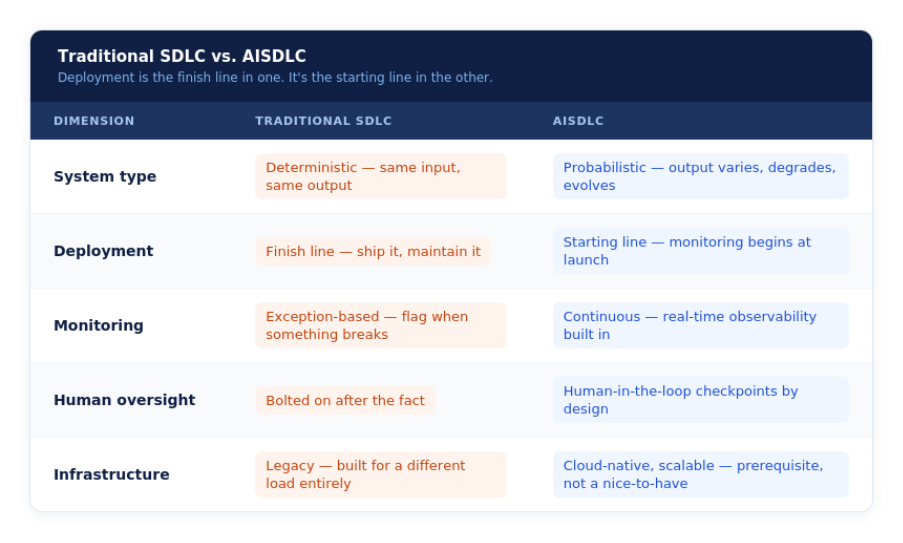
An AI-specific development lifecycle treats deployment as the beginning, not the finish line. Continuous monitoring, dynamic retraining, real-time observability, and human-in-the-loop checkpoints built into the process rather than bolted on afterward. None of this works on legacy infrastructure. Modern, cloud-native, scalable systems aren't a nice-to-have here. They're the prerequisite.
Accenture found that front-running organizations had scaled 34% of their strategic AI bets. The rest of the market had scaled almost none (Source: Accenture, The Front-Runners' Guide to Scaling AI). The difference wasn't the model. It was the infrastructure and lifecycle design underneath it.
What the Value Gap Actually Tells You
Only 17% of organizations can attribute 5% or more of their EBIT to GenAI - in a world where 88% have adopted it (Source: McKinsey & Company, The State of AI in 2025). The adoption metric is measuring the wrong thing.
The gap between adoption and outcomes isn't unique to AI infrastructure. As we explored in Why Enterprise Productivity Is Still Dropping Despite AI Adoption, the measurement problem runs deeper than most dashboards reveal.
AI is like a new hire who immediately reveals every broken system in the office - the unclear processes, the missing documentation, the workflows nobody actually designed. The new hire didn't create the mess. They just made it impossible to ignore. The difference is that a new hire costs a salary. A poorly architected AI system at scale costs margins.
The organizations pulling ahead aren't running better models. They're running better systems around models - on infrastructure designed for scale, through lifecycle processes built for AI rather than borrowed from software development frameworks that predate it entirely.
Building for Scale, Not for the Demo
The model is not the product. The system is the product. And right now, most organizations are evaluating the model while the system underneath it quietly determines whether any of it will ever scale.
The readiness gap is specific, not abstract: governance that can't contain risk, testing infrastructure built for the wrong kind of system, workflows nobody redesigned, and legacy infrastructure that creates bottlenecks before AI ever reaches production. Fix the wiring first, then deploy the model. That sequence is what separates AI implementation that scales from AI implementation that stalls.
The organizations that understand that distinction are the ones still scaling three years from now. Everyone else will be explaining to their board why the demo never became a product.









